
缓存、二级缓存(J2Cache为例)、多级缓存
以器承己,以才示人,以气度世,不虑也。
一、缓存架构
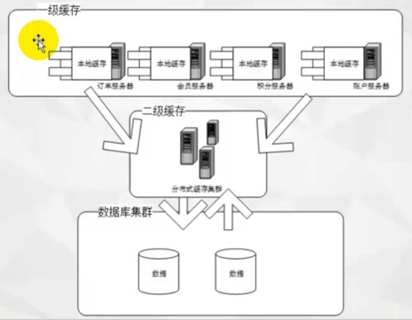
缓存就是将数据从读取较慢的介质上读取出来放到读取较快的介质上,如磁盘到内存。平时我们会将数据存储到磁盘上,如:数据库。如果每次都从数据库里读取,会因为磁盘本身的 IO 影响读取速度,所以就有了像 redis 这种的内存缓存。可以将数据读取出来放到内存里,这样当需要获取数据时,就能够直接从内存中拿到数据返回,能够很大程度提高速度。但是一般 redis 是单独部署成集群,所以会有网络 IO 上的消耗,虽然与 redis 集群的链接已经有连接池这种工具,但是数据传输上也还是会有一定消耗。所以就有了应用内缓存,如:Caffeine。当应用内缓存有符合条件的数据时,就可以直接使用,而不用通过网络到 redis 中去获取,这样就形成了二级缓存。应用内缓存作为一级缓存,远程缓存(如 redis)作为二级缓存。
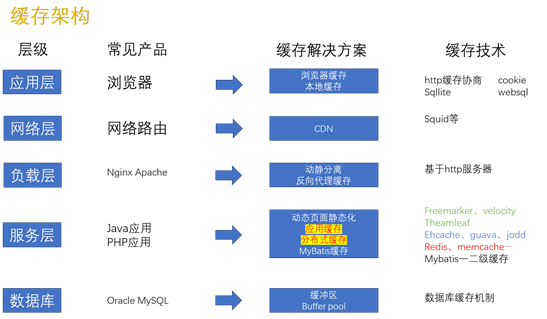
在整个软件架构中,分为的这 5 层每一层都可以添加缓存:
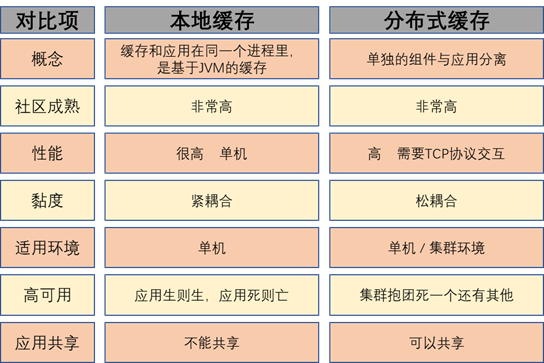
本地缓存(进程内缓存)与分布式缓存(进程外缓存)的对比:
本地缓存之间的对比:
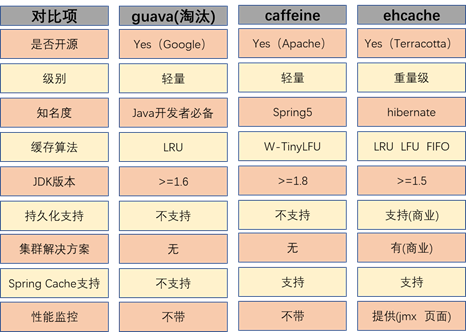
关于本地缓存选型回答:本地缓存中caffeine看非因qps最好,如果jdk,集群,持久化有限制,只能从后两个中选择。
分布式缓存之间的对比:
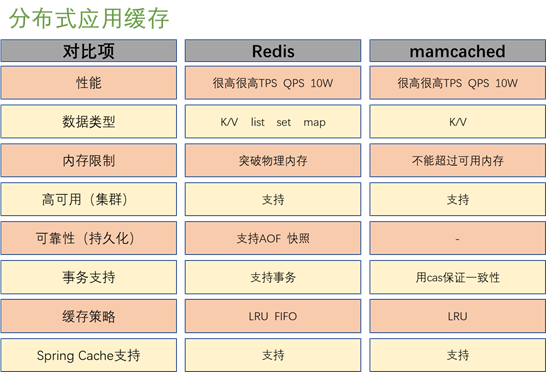
关于分布式应用缓存选型:redis无论在数据类型,内存限制,持久化可靠性,事物的支持还是缓存策略上,都比memcache要好很多,是完全可以取代memcache的。
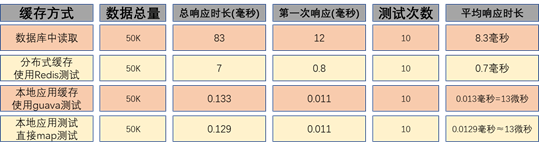
使用不同缓存技术部分对比:
缓存的使用引发的一些典型服务器高可用问题(以 redis 为例):
https://www.cnblogs.com/laiyw/p/15174422.html
缓存穿透:
缓存穿透,是指查询一个数据库一定不存在的数据。用户想要查询一个数据,发现 redis 内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询。发现也没有,于是本次查询失败。当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库。这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
| 解决方案: |
布隆过滤器:布隆过滤器是一种数据结构,对所有可能查询的参数以 hash 形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
缓存空对象:当缓存层不命中后,即使返回的空对象也将其缓存起来,同时会设置一个过期时间,之后再访问这个数据将会从缓存中获取,保护了后端数据源;
但是这种方法会存在两个问题:
1、如果空值能够被缓存起来,这就意味着缓存需要更多的空间存储更多的键,因为这当中可能会有很多空值的键;
2、即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿:
缓存击穿,是指一个 key 非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个 key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,这类数据一般是热点数据。比如说:微博又有明星出轨了,大量用户请求去请求同一个东西,这个时候缓存某个 key 设置的过期时间是 60s,60.1s 缓存恢复了,在这 0.1s 的时间内,大量的请求就跑到了 MySQL 关系型数据库里面了,容易使数据库宕机,这就是击穿!
| 解决方案: |
设置热点数据永不过期:从缓存层面来看,没有设置过期时间,所以不会出现热点 key 过期后产生的问题。
加互斥锁:分布式锁:使用分布式锁,保证对于每个 key 同时只有一个线程去查询后端服务,其他线程没有获得分布式锁的权限,因此只需要等待即可。这种方式将高并发的压力转移到了分布式锁,因此对分布式锁的考验很大!
缓存雪崩:
缓存雪崩,是指在某一个时间段,缓存集中过期失效。产生雪崩的原因之一,比如马上就要到双十一零点,很快就会迎来一波抢购,这波商品时间比较集中的放入了缓存,假设缓存一个小时。那么到了凌晨一点钟的时候,这批商品的缓存就都过期了。而对这批商品的访问查询,都落到了数据库上,对于数据库而言,就会产生周期性的压力波峰。于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
其实集中过期,倒不是非常致命,比较致命的缓存雪崩,是缓存服务器某个节点宕机或断网。因为自然形成的缓存雪崩,一定是在某个时间段集中创建缓存,那么那个时候数据库能顶住压力,这个时候,数据库也是可以顶住压力的。无非就是对数据库产生周期性的压力而已。而缓存服务节点的宕机,对数据库服务器造成的压力是不可预知的,很有可能瞬间就把数据库压垮。
| 解决方案: |
redis高可用:
既然 redis 有可能挂掉,那就多增设几台 redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群。
限流降级:
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个 key 只允许一个线程查询数据和写缓存,其他线程等待。
数据预热:
在正式部署之前,先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的 key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
设计分布式缓存时需要考虑(一致性问题):
• 如何知道集群环境中的其他缓存?
• 分布式传送的消息是什么形式?
• 什么情况需要进行复制?增加(Puts),更新(Updates)或是失效(Expiries)?
• 采用什么方式进行复制?同步还是异步方式?
标题:缓存、二级缓存(J2Cache为例)、多级缓存
作者:amethystfob
地址:https://newmoon.top/articles/2021/10/18/1634567217022.html
欢迎各路大侠指点留痕: